KI-gestützte Cyberangriffe: Low-Skill-Hacking wird skalierbar

TL;DR
KI hat Hacking nicht magisch gemacht – sie hat es industrialisiert. Standardmethoden (Scannen, Credential Abuse, Konfigurationsauswertung) werden durch KI zum Fließband: Grenzkosten pro Angriff sinken, Low-Skill-Akteure können massenhaft Ziele treffen. Die Abwehr bleibt oft klassisch: Managementflächen nicht ins Internet, MFA, Passwortdisziplin, Patchen. Dieser Artikel erklärt das Risiko und priorisiert Maßnahmen – mit einer Fallstudie als Beleg.
Stand: 25. Februar 2026 – zuletzt aktualisiert
Autor: Mika Schmidt (IT-Security Consultant) – Six Eight Consulting, Fokus: Analyse, IAM, Security Engineering.
KI hat Hacking nicht magisch gemacht – sie hat es industrialisiert. KI-gestützte Cyberangriffe (engl. AI-augmented attacks) machen aus dem, was früher „zu aufwendig“ war – internetweites Scannen, massenhaftes Testen von Zugangsdaten, Auswertung von Konfigurationen – ein skalierbares Risiko. Einzelne Akteure mit begrenzter eigener Expertise können Kampagnen fahren, die früher Infrastruktur und Team erfordert hätten. Für Unternehmen verschiebt sich die Gefahr: Nicht nur Zero-Days zählen, sondern die klassischen Schwachstellen – exponierte Management-Oberflächen, Passwort-only-Zugänge, Passwortwiederverwendung, Patch-Lücken – werden in der Summe zum Massenrisiko.
In diesem Artikel erfahren Sie, was AI-augmentiertes Low-Skill-Hacking ausmacht, warum „alte“ Angriffe dadurch wieder gefährlich werden und welche Maßnahmen Sie priorisieren sollten. Eine konkrete Fallstudie (Threat Intelligence 2026) dient als Beleg – der Fokus liegt auf dem zeitlosen Muster, nicht auf einem einzelnen Hersteller.
- Nach rund 8 Minuten wissen Sie, was KI-gestützte Angriffsautomatisierung ist und warum Grenzkosten pro Angriff sinken.
- Sie verstehen die typische Angriffskette (Scan → Credential Abuse → Recon → Backup/Recovery) und den Multiplikator „Identität“.
- Sie haben eine priorisierte Liste von Schutzmaßnahmen und können Ihren eigenen Stand prüfen (Exposure, MFA, Patchen).
Was ist AI-augmented Low-Skill-Hacking?
Kurz definiert
AI-augmented Low-Skill-Hacking (oder KI-gestütztes Low-Skill-Hacking) bezeichnet Kampagnen, in denen Angreifer mit begrenzter eigener Engineering-Tiefe kommerzielle KI-Dienste nutzen, um Standardmethoden zu automatisieren und zu skalieren: Scannen exponierter Dienste, Credential Stuffing bzw. Password Guessing, Auswertung von Konfigurationsdaten, Recon und Post-Exploitation. Erfolg entsteht weniger durch neuartige Exploits als durch die Kombination aus großer Angriffsfläche, schwacher Abwehrhygiene (exponierte Admin-Oberflächen, fehlende MFA, Patch-Lücken) und KI als „Force Multiplier“ für Skripte, Parser und Playbooks.
- Managementflächen im Internet? → Als kritisch einstufen – sofort Abschirmung und MFA prüfen.
- Nur Passwort-Schutz auf Admin-Zugängen? → Credential Stuffing und Wiederverwendung machen Sie zum skalierbaren Ziel.
Warum KI „alte“ Angriffe wieder gefährlich macht
Skalenökonomie: Grenzkosten pro Versuch sinken
Internetweites Scanning ist seit Jahren technisch möglich, aber die Operationalisierung – Tooling, Datenauswertung, Fehlerbehandlung, Priorisierung – war ein Skill- und Zeitfresser. Bereits vor über einem Jahrzehnt zeigten Studien, dass ein einzelnes Tool das gesamte IPv4-Adressspektrum für einen Port in unter einer Stunde scannen kann. Aktuelle Telemetrie aus großen Netz-Teleskopen und Port-Statistiken zeigt eine massive Zunahme von Scanning über das letzte Jahrzehnt – in einigen Beobachtungen Größenordnungen von deutlich höherem Volumen als noch vor Jahren. [Daten] [Report]
KI wirkt als „Kopplungsstück“, das aus Rohdaten schneller handlungsfähige Listen und Workflows macht: Code schreiben, Logs parsen, Treffer priorisieren, nächste Schritte planen. Das Ergebnis ist kein „Genie-Exploit“, sondern KI als Beschleuniger für Standardmethoden – und damit sinken die Grenzkosten pro Angriffsversuch in Richtung null.
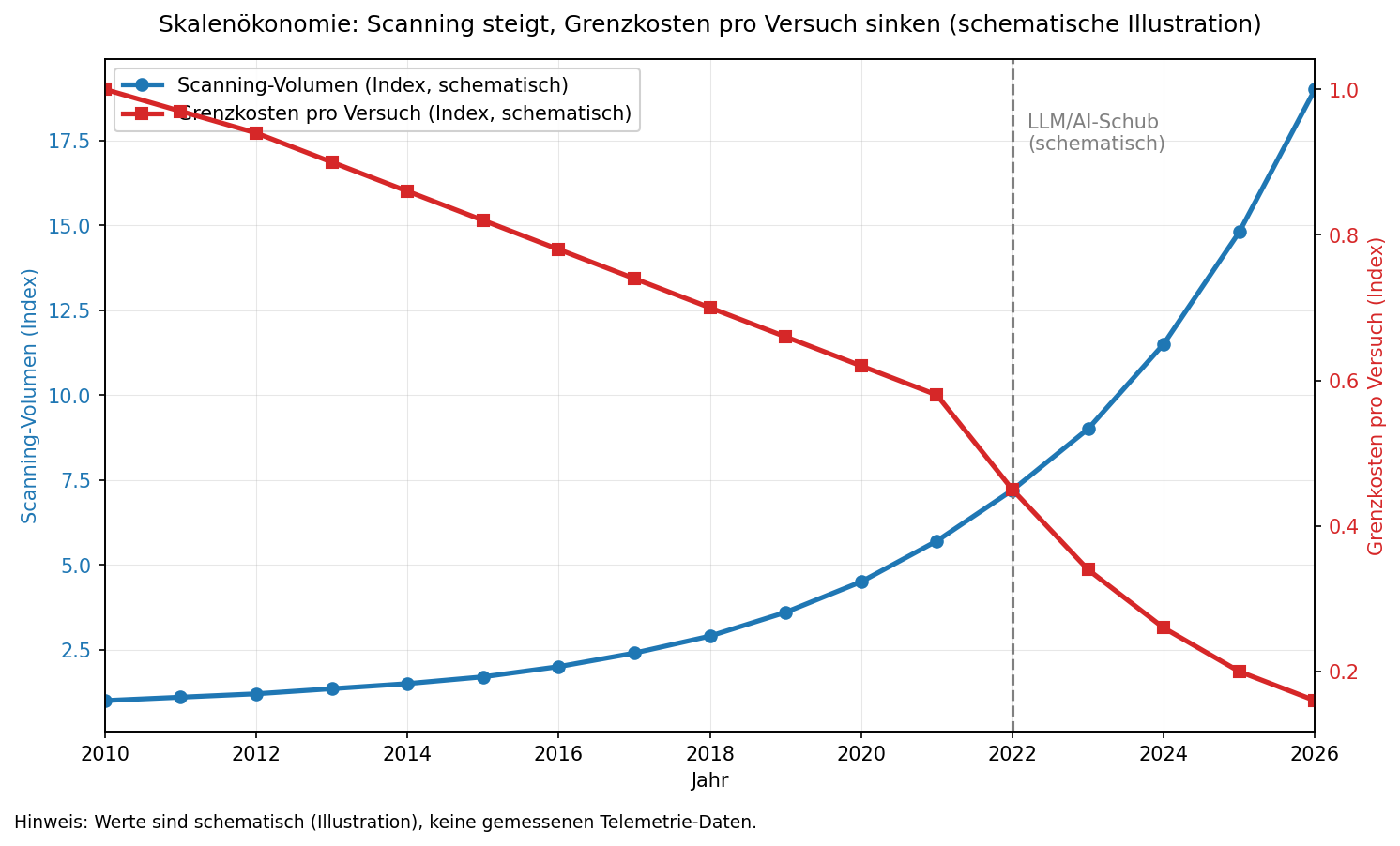
Geschwindigkeit: Tooling, Parsing, Playbooks
In kontrollierten Studien erledigten Entwickler mit einem Code-Assistenten Programmieraufgaben deutlich schneller als ohne (Größenordnung 50 %+ Zeitersparnis). [Forschung] Übertragen auf Angreifer: Skripte, Glue-Code, Parser und Scanner-Kombinationen entstehen schneller. Genau diese „kleinen“ Tools entscheiden in Massenkampagnen über Skalierung. Gleichzeitig strukturiert KI Konfigurationsdaten und Logs, generiert Recon-Schritte und sogar Angriffspläne mit Priorisierung – „Low-Skill“-Akteure können dadurch konsistent „mittelgut“ operieren, ohne tiefes Exploit-Engineering.
Identität als Multiplikator: Passwortwiederverwendung und MFA-Lücken
Viele erfolgreiche Kampagnen kommen ohne ausgefeilte Exploits aus, wenn Identität schwach abgesichert bleibt: exponierte Web-Management-Ports plus Credential Abuse (gestohlene oder wiederverwendete Zugangsdaten) reichen für Initial Access. Externe Daten belegen, dass Passwortmissbrauch systemisch skaliert:
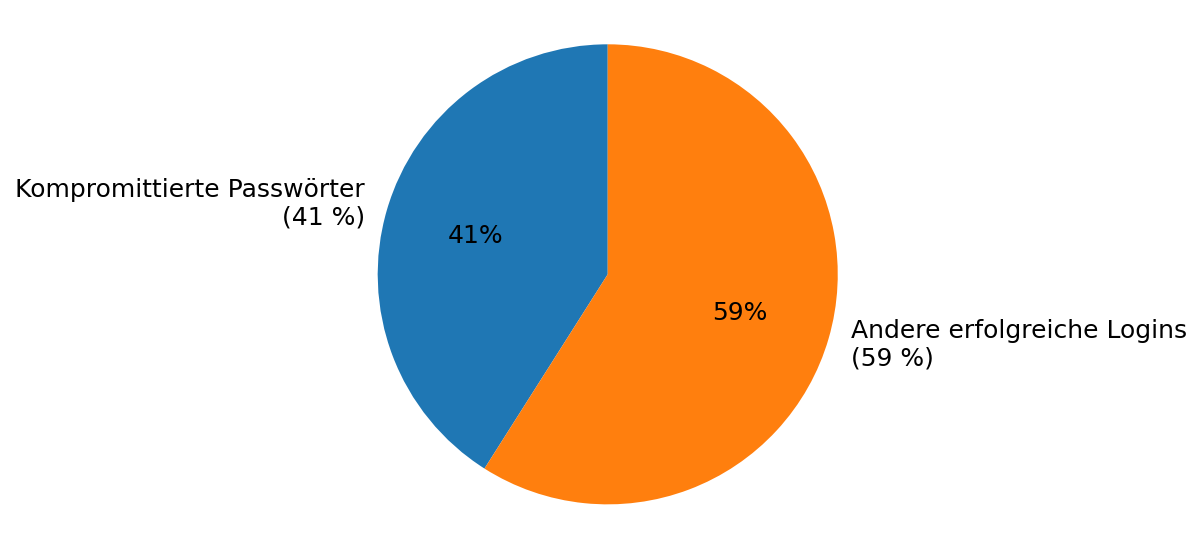
- Cloudflare (Sep–Nov 2024): 41 % der erfolgreichen Logins betreffen kompromittierte Passwörter – starker Indikator für Wiederverwendung und Credential Stuffing-Effektivität. [Analyse]
- Verizon (DBIR): Kompromittierte Zugangsdaten in 22 % der Breaches als Initial Access; in einem Infostealer-Datensatz nur 49 % der Passwörter je Person über Dienste hinweg eindeutig. [Research]
- F5: Automation und „malicious login attempts“ bleiben in großem Maßstab präsent – z. B. zweistellige Prozentanteile im Login-Traffic, Spitzenwerte bis über 33 % (Web, Technologie-Branche). [Report]
MFA ist die naheliegende „Kante“, an der sich Credential Stuffing bricht – doch die Adoption bleibt unvollständig (z. B. Industrie-Adoptionsraten typischerweise 60–80 %, in Deutschland nur rund die Hälfte der Unternehmen mit fortgeschrittener Benutzeridentifikation/2FA; über 99 % kompromittierter Accounts ohne MFA). [Report] [Studie] [Hinweis]
Pull-Quote: „Mehr als 99,9 % kompromittierter Accounts hatten keine MFA – Passwörter bleiben ein Single Point of Failure.“
Patch-Latenz & Exposure: bekannte Lücken in Masse
KI macht nicht nur Credential-Workflows schneller, sondern verstärkt den Effekt bekannter CVEs, weil Angreifer Patch-Lücken schneller ausnutzen können als viele Organisationen schließen. Beispiel: Eine kritische SSL-VPN-Schwachstelle in weit verbreiteten Perimetergeräten wurde vom Hersteller gepatcht – dennoch meldeten Beobachter noch Wochen später über 130.000 potentiell betroffene exponierte Geräte. [PSIRT] [News]
Der Mechanismus ist derselbe: Sobald Abwehrhygiene nicht konsistent ist (Patch, Admin-Exposure, MFA), wird die Schwäche zu einem skalierbaren Problem – und KI reduziert die Grenzkosten pro zusätzlichem Ziel. Die Angriffsfläche ist riesig: Globale Port-Statistiken zeigen zweistellige Millionenwerte allein für typische HTTPS-/Management-Ports (443, 8443, 10443, 4443). [Daten]
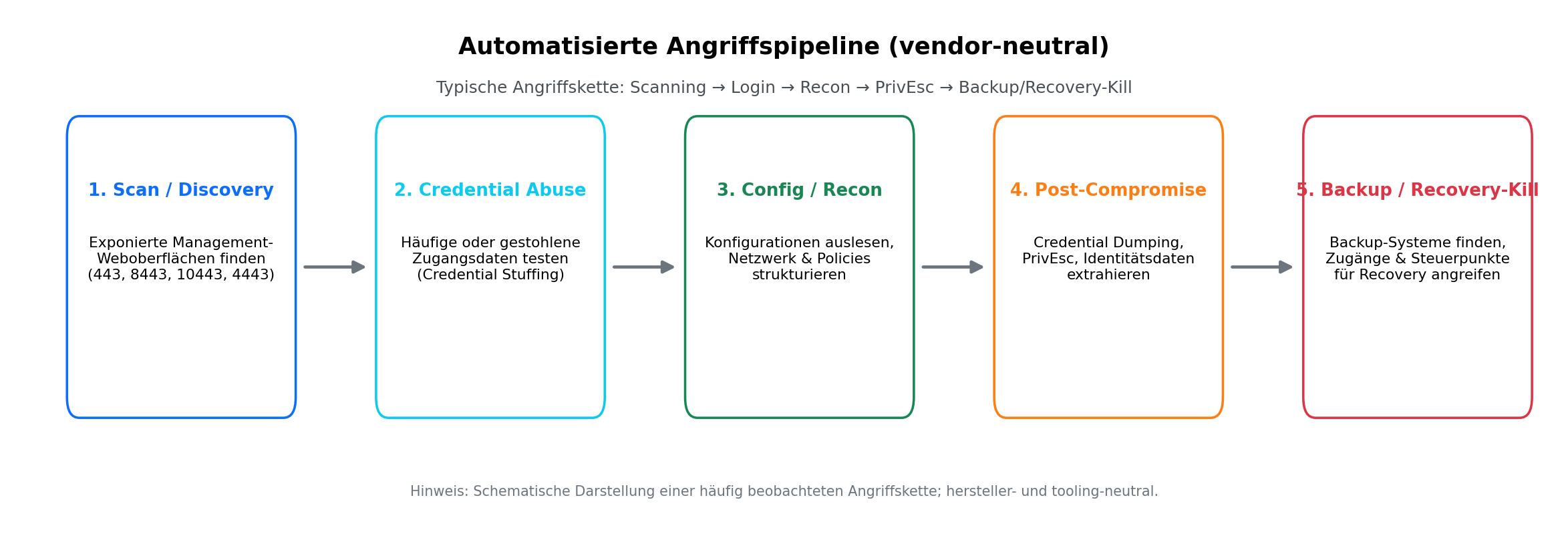
Typische Angriffskette (vendor-neutral)
Das beobachtbare Muster ist herstellerübergreifend:
- Scan/Discovery: Internetweites Auffinden exponierter Management-Weboberflächen (typische Ports: 443, 8443, 10443, 4443).
- Credential Abuse: Testen häufiger oder gestohlener Zugangsdaten; teils Wiederverwendung zwischen Geräten oder Diensten.
- Config/Recon: Auslesen und Strukturieren von Gerätekonfigurationen – Kartierung von Netzwerksegmenten, VPN-Einstellungen, Benutzer- und Policy-Strukturen.
- Post-Compromise/PrivEsc: Einsatz etablierter Offensiv-Tools (z. B. Credential Dumping, DCSync) zur Extraktion von Identitätsdaten.
- Backup/Recovery-Kill: Gezielte Suche nach Backup-Systemen (z. B. Veeam Backup & Replication), um an Zugangsdaten und Steuerungspunkte der Backup-Infrastruktur zu gelangen – bekannte Vorstufe für Ransomware- oder „Recovery-Prevention“-Taktiken.
Fallstudie: Kompromittierte Perimetergeräte in Serie (Beispiel 2026)
Die folgende Box fasst eine konkrete Kampagne zusammen, die von Threat-Intelligence (AWS) beobachtet wurde. Sie dient als Beleg für das beschriebene Muster – nicht als Hauptstory. Wer ausschließlich an diesem einen Fall interessiert ist, findet die Kernzahlen und TTPs hier; für die langfristige Einordnung zählt das allgemeine Risiko (siehe Abschnitte oben und unten).
Beispiel aus der Praxis: Kampagne gegen exponierte Perimeter- und Management-Systeme
Zeitraum: 11.01.2026 – 18.02.2026.
Beobachteter Umfang: Ein einzelner Akteur kompromittierte über 600 Perimetergeräte (konkret: Fortinet FortiGate) in 55 Ländern. AWS betont, dass weder AWS- noch Amazon-Systeme kompromittiert wurden; es handelt sich um externe Threat-Intelligence.
[Threat Intelligence]
Angriffsweg: Kein Zero-Day – sondern exponierte Web-Management-Ports, Credential Abuse (Password Guessing/Stuffing), Konfigurations-Parsing, Post-Exploitation (u. a. DCSync) und gezieltes Targeting von Backup-Systemen (z. B. Veeam). Der Akteur nutzte kommerzielle KI-Dienste für Code-Generierung (Python/Go), automatisierte Auswertung von Konfigurationsdaten und KI-generierte Angriffspläne/Playbooks. Fortgeschrittene Exploits scheiterten oft (Anpassung/Kompilierung/Debug an Zielumgebungen).
Fazit: Erfolgsquote muss nicht hoch sein – wenn Grenzkosten pro Versuch durch Automatisierung/KI gegen null gehen, reicht eine niedrige Trefferquote für Hunderte Kompromittierungen. Schätzung (auf Basis externer Proxies für exponierte Zielsysteme): grob 0,1–1 % Erfolgsquote; Aussagekraft wie im Haupttext erläutert. [Analyse]


Pre-AI vs. AI-augmentiert: Was sich verändert
Vergleich: Pre-AI vs. AI-augmentierter Angreifer
Die folgende Tabelle verdichtet, was in beobachteten Kampagnen und in Telemetrie/Reports zur „Automation Economy“ sichtbar wird (u. a. F5, Shodan, Verizon, Cloudflare, AWS Threat Intelligence).
| Dimension | „Pre-AI“ (klassisch) | AI-augmentiert (2026-Realität) | Typische Auswirkung |
|---|---|---|---|
| Tooling/Script-Erstellung | Manuelles Coden/Debuggen; hohe Hürde für Multi-Language & Robustheit | Prompt → Code in Minuten; Iteration/Refactor schnell (aber fehleranfällig) | Mehr Targets pro Zeiteinheit; mehr Variationen/Anpassungen |
| Recon & Datenaufbereitung | Viel Handarbeit: Parsing, Normalisierung, Priorisierung | KI strukturiert Logs/Configs, generiert Queries & Recon-Schritte | Schnellere „Time-to-Next-Step“ nach Initial Access |
| Kampagnen-Planung | Erfahrungswissen erforderlich; Lernkurve steil | KI generiert Playbooks, Entscheidungsbäume, Prioritäten | „Low skill“ kann konsistent „mittelgut“ operieren |
| Exploit-Engineering | Hohe Expertise nötig | KI hilft beim Kopieren/Anpassen, aber Debug/Edge-Cases schwierig | Häufige Failures bei komplexen Exploits; Erfolg v. a. bei Hygiene-Lücken |
| Skalierung | Botnet/Infra/Team erforderlich | Einzelperson kann „Assembly line“ fahren | Mehr Opportunismus, mehr Breite, schnelleres Pivoting |
Erfolgsquote: Warum schon geringe Quoten reichen
Threat-Intelligence-Quellen veröffentlichen oft keine rohe Scananzahl oder Erfolgsquote. Für die Einordnung reicht das Prinzip: Wenn der Target-Space groß ist (z. B. Hunderttausende exponierter Management- oder VPN-Interfaces weltweit) und die Grenzkosten pro Versuch durch Automatisierung/KI gegen null gehen, reicht eine niedrige Erfolgsquote (Größenordnung 0,1–1 %) für Hunderte Kompromittierungen. Die Fallstudie oben (über 600 Treffer in 55 Ländern durch einen Akteur) belegt das Muster; die genaue Quote hängt vom konkreten Zielraum ab.
Was Unternehmen jetzt tun müssen: priorisierte Schutzmaßnahmen
Die Abwehr bleibt oft „klassisch“: Managementflächen nicht ins Internet, MFA, Passwortdisziplin, Patchen. Das ist konsistent mit der Unternehmensrealität in Deutschland: Laut BfV/Bitkom lagen Schäden durch Diebstahl/Spionage/Sabotage zuletzt bei 289,2 Mrd. €, davon 202,4 Mrd. € durch Cyberattacken; 59 % der befragten Unternehmen sehen sich existenziell bedroht. [Presse]
Schnell-Check vor den Maßnahmen – 5 Punkte
- Sind Management- oder Admin-Oberflächen (Firewall, VPN, Backup) aus dem Internet erreichbar?
- Schützen Admin- und Remote-Zugänge MFA (idealerweise phishing-resistent)?
- Werden Admin-Passwörter ausschließlich für diese Systeme genutzt (kein Wiederverwenden)?
- Gibt es ein klares Exposure- und Patch-Management für Perimetergeräte mit Fristen?
- Werden Edge-Logs, IdP- und MFA-Events sowie Login-Anomalien ausgewertet?
Pull-Quote:
„Die Frage ist nicht, ob Unternehmen angegriffen werden, sondern wann – und ob sie erfolgreich abwehren können.“
| Maßnahme | Zweck gegen AI-augmentierte „Low-Skill“-TTPs | Aufwand | Kosten | Security-Impact |
|---|---|---|---|---|
| Managementflächen nicht öffentlich erreichbar | Entfernt die „Sichtlinie“ für Massenscans/Password-Guessing | Mittel (Netz/Firewall) | Niedrig–Mittel | Sehr hoch |
| MFA für Admin-/Remote-Zugänge (phishing-resistent) | Bricht Credential Stuffing/Reuse als Haupthebel | Mittel (Rollout/UX) | Niedrig–Mittel | Sehr hoch |
| Admin-Passwörter & Credentials getrennt halten (kein Reuse) | Verhindert „Sprungbrett“-Effekt nach Gerätekompromittierung | Mittel | Niedrig | Hoch |
| Patch- & Exposure-Management für Perimetergeräte mit SLA | Reduziert „Long Tail“ bekannter CVEs (zehntausende Geräte bleiben oft verwundbar) | Mittel–Hoch | Mittel | Sehr hoch |
| Monitoring/Detection auf „Edge“ + MFA/IdP-Logs | Erhöht Chance, „low noise“ Credential Abuse zu entdecken | Mittel | Mittel | Hoch |
| Backup-Härtung (Segmentierung, Port-Restriktion, Admin-Tiering) | Verhindert den „Recovery Kill Switch“; Backup-Systeme sind häufiges Ziel (z. B. Veeam und andere) | Mittel | Mittel | Sehr hoch |
| Bot-/Rate-Limiting / Anomaly Detection für Login-Endpunkte | Reduziert Credential-Stuffing-Volumen (F5: zweistellige %-Raten im Login-Traffic) | Mittel | Mittel–Hoch | Mittel–Hoch |
| Incident-Playbooks & Recovery-Tests | Verkürzt Ausfallzeiten und vermindert Erpressbarkeit | Mittel | Niedrig–Mittel | Hoch |
Viele Hersteller von Perimetergeräten und Firewalls empfehlen in ihren Hardening-Guides explizit, administrative Zugriffe von externen Interfaces zu deaktivieren (z. B. HTTPS/SSH nur intern oder über gesicherte Zugangspfade). Ein Beispiel für dokumentierte Best Practices ist die Fortinet-FortiGate-Dokumentation. [Best Practice]
Quick-Check: Grundlagen zu Risiken und Maßnahmen finden Sie im Artikel IT-Security-Grundlagen für kleine Unternehmen. Wenn Sie unsicher sind, ob Ihr Setup ausreicht: Ein IT-Security Check (Exposure & Hardening) oder Projektbegleitung für Patch-Management & Hardening bringt Struktur.
Annahmen und Limitationen
- Zu konkreten Kampagnen liegen oft keine veröffentlichten Rohdaten zu Scanvolumen, Attempt-Zahlen oder Erfolgsquoten vor; Threat-Intelligence nennt typischerweise Opfer- und Länderanzahl, TTPs und qualitative Beobachtungen.
- Schätzungen (Erfolgsrate) basieren, wo angegeben, auf externen Proxies (z. B. Größenordnungen exponierter Interfaces) und sind bewusst als Bandbreiten formuliert.
- Port-Exposure-Zahlen (z. B. Shodan) sind global aggregierte Banner Counts, nicht produktspezifische Install-Basen.
- Geografische Darstellungen sind mangels veröffentlichter Fallzahlen pro Region oft qualitativ.
- Der KI-Beitrag ist kontextabhängig: Beobachtungen belegen den Force-Multiplier-Effekt für Routineangriffe, zeigen aber zugleich Grenzen bei komplexem Exploit-Engineering.
Häufige Fragen
Wie verändert KI Cyberangriffe?
KI beschleunigt und skaliert vor allem Routineangriffe: Code für Scans und Credential-Tests wird per Prompt generiert, Konfigurationsdaten und Logs werden automatisiert ausgewertet, Angriffspläne und Playbooks entstehen mit KI-Unterstützung. Das senkt die Grenzkosten pro Versuch und ermöglicht Einzelpersonen, kampagnenartig viele Ziele zu treffen. Komplexe Exploits ersetzt KI dagegen nicht – dafür fehlt oft das tiefe Exploit-Engineering.
Warum sind Credential-Stuffing-Angriffe so erfolgreich?
Weil Passwortwiederverwendung weit verbreitet ist und viele Admin- oder Remote-Zugänge nur mit Passwort geschützt sind. Studien zeigen z. B. 41 % erfolgreiche Logins mit kompromittierten Passwörtern, 22 % der Breaches mit kompromittierten Zugangsdaten als Initial Access und unter 50 % wirklich eindeutige Passwörter pro Person über Dienste hinweg. Ohne MFA wird Credential Stuffing zum skalierbaren Risiko.
Hilft MFA wirklich gegen KI-gestützte Angriffe?
Ja. KI skaliert vor allem Angriffe, die auf gestohlene oder erratene Passwörter setzen. MFA (idealerweise phishing-resistent) bricht diesen Hebel: Credential Stuffing und einfaches Password Guessing reichen dann nicht mehr. Über 99 % kompromittierter Accounts hatten keine MFA – die Maßnahme bleibt eine der wirkungsvollsten gegen automatisierten Credential Abuse.
Welche Maßnahmen bringen am meisten?
Priorität haben: Managementflächen nicht öffentlich erreichbar machen, MFA für Admin- und Remote-Zugänge erzwingen, Admin-Passwörter und Credentials getrennt halten (kein Wiederverwenden), Patch- und Exposure-Management für Perimetergeräte mit SLA, Monitoring auf Edge und MFA/IdP-Logs, Backup-Härtung (Segmentierung, Port-Restriktion), Bot-/Rate-Limiting und Incident-Playbooks. Ein strukturierter Einstieg hilft, wenn Ressourcen begrenzt sind.
Woran erkennt man AI-augmented Scanning oder Credential Abuse?
Typische Signale: massenhaftes Scanning auf typische Management-Ports (z. B. 443, 8443, 10443, 4443), hoher Anteil automatisierter oder fehlgeschlagener Login-Versuche, ungewöhnliche geografische oder zeitliche Muster bei Zugriffen. Monitoring von Edge-Logs, IdP- und MFA-Events sowie Anomalie-Erkennung auf Login-Endpunkten erhöhen die Chance, solche Kampagnen zu entdecken.
Detection Signals – worauf achten?
- Edge-Logs: Massenhaftes Scanning auf Management-Ports (443, 8443, 10443, 4443), viele Requests von wenigen IPs oder Bot-Muster.
- IdP / Anmeldung: Hoher Anteil fehlgeschlagener Logins, ungewöhnliche Zeiten oder Regionen, gleiche User-Agents/Pattern.
- MFA-Events: Viele Challenge-Versuche oder Umgehungsversuche; MFA-Failures nach Credential-Änderungen.
- Rate-Spikes: Plötzliche Anstiege bei Login- oder Scan-Requests – Anomalie-Erkennung und Rate-Limiting helfen.
Pull-Quote:
„Wenn Managementzugänge im Internet stehen und nur ein Passwort schützen soll: Das ist heute kein ‚hohes Risiko‘, sondern ein skalierbares Risiko.“
Pull-Quote:
„41 % der erfolgreichen Logins enthalten kompromittierte Passwörter – Wiederverwendung macht Credential Stuffing zum Massenphänomen.“
Quellen & weiterführende Links
Offizielle Threat Intelligence, Advisories und technische Analysen:
AI-Augmented Threat Actor Accesses FortiGate Devices at Scale
Amazon Web Services Security Blog, 2026
Amazon: Hacker nutzte KI-Tools für FortiGate-Breach
HackRead, 2026
Shodan – Port Statistics
Shodan, Zugriff 2026
Password Reuse Rampant – Half of User Logins Compromised
Cloudflare, Sep–Nov 2024
Credential Stuffing Attacks – 2025 DBIR Research
Verizon, 2025
Secure Sign-In Trends Report 2025
Okta, 2025
Bitkom-Studie – Deutsche Wirtschaft gegen Diebstahl, Spionage, Sabotage
BfV/Bitkom, 2025
F5 Labs – 2025 Advanced Persistent Bots Report
F5, 2025
FG-IR-24-015 – FortiOS SSL-VPN Critical Vulnerability (CVE-2024-21762)
Fortinet, 2024
Deutsche Wirtschaft gegen Diebstahl, Spionage, Sabotage
Bitkom, 2025
The Impact of AI on Developer Productivity
arXiv, 2023
CVE-2023-27997 – Exploitable FortiGate Vulnerable
Bishop Fox
Veeam KB4424 – Security Advisory
Veeam
NVD – CVE-2023-27532 (Veeam Backup & Replication)
NIST NVD
NVD – CVE-2024-40711 (Veeam Deserialization/RCE)
NIST NVD
Critical Fortinet flaw may impact 150,000 exposed devices
BleepingComputer, 2024
FortiGate – System Administrator Best Practices (Hardening)
Fortinet Documentation
Security at your organization (MFA)
Microsoft
Stand: 25.02.2026
Dieser Artikel wird bei neuen Entwicklungen aktualisiert. Für aktuelle Informationen prüfen Sie bitte die offiziellen Quellen (Threat Intelligence, Hersteller-Advisories, BSI).
Sie möchten diese Schritte auf Ihr Unternehmen übertragen?
In einem kurzen Gespräch klären wir, welche Maßnahmen für Sie konkret sinnvoll sind – ohne Over-Engineering. Weitere Artikel finden Sie im Blog-Archiv.